



AI technology continues to evolve rapidly, driven by massive amounts of high-quality training data. To build smarter systems—whether in autonomous driving, voice assistants, or machine translation—global enterprises are partnering with language service providers (LSPs) to develop multilingual datasets.
Hansem Global is one such trusted partner, working with global clients like Uber to deliver language-based AI data projects. In this article, we provide a practical guide for those looking to join AI data labeling projects: what data labeling is, what roles are available, what qualifications are needed, and how to get started.
1. Why Now Is the Right Time to Join an AI Project
From voice assistants to real-time translation, AI technology is now part of everyday life. Behind these technologies are large-scale datasets that require human input—this is where data labeling becomes essential.
To ensure accuracy and reliability, global tech companies like Google, Amazon, Meta, and Uber are working with language experts and multilingual contributors worldwide. Increasingly, they rely on professional LSPs to manage these operations efficiently and securely.
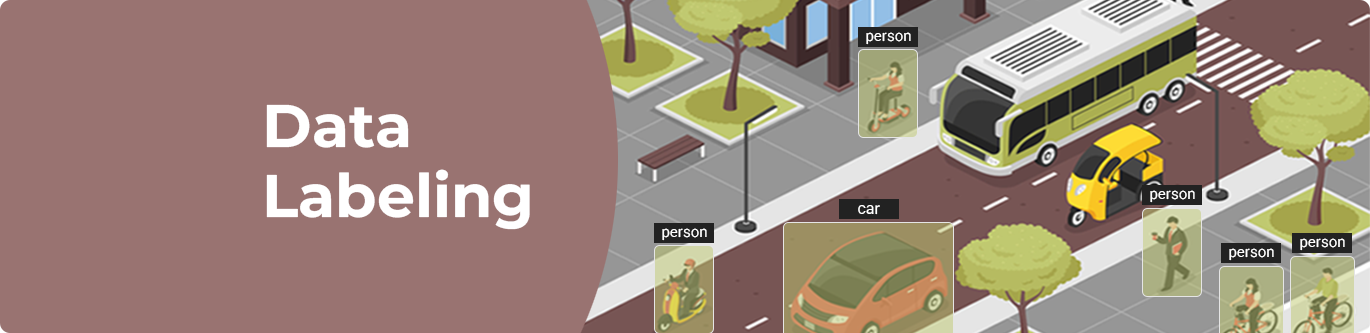
2. What Is Data Labeling?
Data labeling is the process of attaching informative tags—“labels”—to various types of raw data so that AI systems can learn from them. Examples include:
- Identifying whether an image shows a cat or a dog
- Tagging customer reviews as positive or negative
- Transcribing audio files into text
- Marking named entities (e.g., person, organization, location) in a sentence
Those who perform this work are often called data labelers, data annotators, or AI data contributors.
3. Why Do Language Service Providers (LSPs) Lead These Projects?
AI models don’t just require large volumes of data—they require accurate, contextual, and linguistically appropriate data.
That’s why global enterprises trust LSPs like Hansem Global. As a multilingual expert hub, we offer:
- Native-level contributors in over 50 languages
- Proven quality management systems
- Hands-on experience with multilingual project delivery
- Strict compliance with security policies and NDAs
These capabilities are essential to deliver the high-quality, high-precision data needed to train reliable AI systems.
4. Types of Tasks and Required Skill Levels
AI data labeling projects vary in complexity. We group them into three skill levels:
| Level | Task Examples | Required Skill |
| L1 | Simple tagging, similarity checks | Basic language understanding |
| L2 | Text classification, translation evaluation | Language majors or translators |
| L3 | Legal/medical content review, terminology tagging | Domain knowledge and linguistic expertise |
No prior experience? No problem. Many contributors start with L1 tasks and gradually take on more complex roles with training and support.
5. Why You Need a PKT Test
Before joining a project, most companies require a Project Knowledge Test (PKT). This is not just a skills test—it’s used to verify that you fully understand the rules and guidelines of the specific project.
- Each project has a different PKT (e.g., Uber PKT, Amazon PKT)
- Your PKT score determines whether you’re assigned to the project
- Some PKT scores may influence task rates
6. Why Onboarding Matters
Once you’re onboarded, you’ll be eligible for fast-track participation in future projects. This is especially important for rare language speakers.
- Access more opportunities after initial onboarding
- Work flexibly without time constraints
- Remote participation possible regardless of your location
(Language and cultural understanding required)
Note: Some projects may require work in specific time zones or prioritize contributors in certain countries.
7. Why Identity Verification Is Required
Most global clients require identity verification for contributors. This ensures data quality and legal compliance, especially when dealing with sensitive, real-world data. Key reasons include:
- Protection of sensitive AI training data (e.g., personal speech, private messages)
- Compliance with GDPR, CCPA, and other privacy regulations
- Trust and traceability in international contracts
You may be asked to provide:
- Proof of residence or nationality
- Passport or national ID
- NDA signature
- Consent to data monitoring and privacy terms
These steps are essential to maintaining transparency and trust in AI development.
Hansem Global Is Recruiting Contributors for AI Projects
As an official partner of globally well-known clients, Hansem Global leads a wide range of language-based AI projects, including text classification, voice transcription, sentiment analysis, and terminology tagging.
We are continuously onboarding multilingual contributors across all skill levels (L1 to L3) to support diverse AI initiatives.
We are especially seeking contributors who meet the following criteria:
- Native speakers of Simplified Chinese (Mainland China), Traditional Chinese (Taiwan), Chinese (Singapore), or Japanese
- Able to accurately understand and follow English-language task instructions
- Residing locally in their respective countries or regions
Data labeling is not just repetitive work—it’s a key component of ethical, accurate, and responsible AI development. If you’re interested in joining our contributor network, please send your application or inquiry to resource@hansem.com. Gain early access to global AI projects and help shape the future of language-driven technology.